

Here are four sequences, showcasing how on-call responders can enhance their operations by adopting an incident alert management platform:
Workflow One: Incident Alerting-Ticketing System Integration
Incident resolution is made easy with an intelligent alerting-ticketing system integration. In this sequence, a client simply contacts his support team through a customer-support portal. Here, the client describes his issue and provides details about the situation.
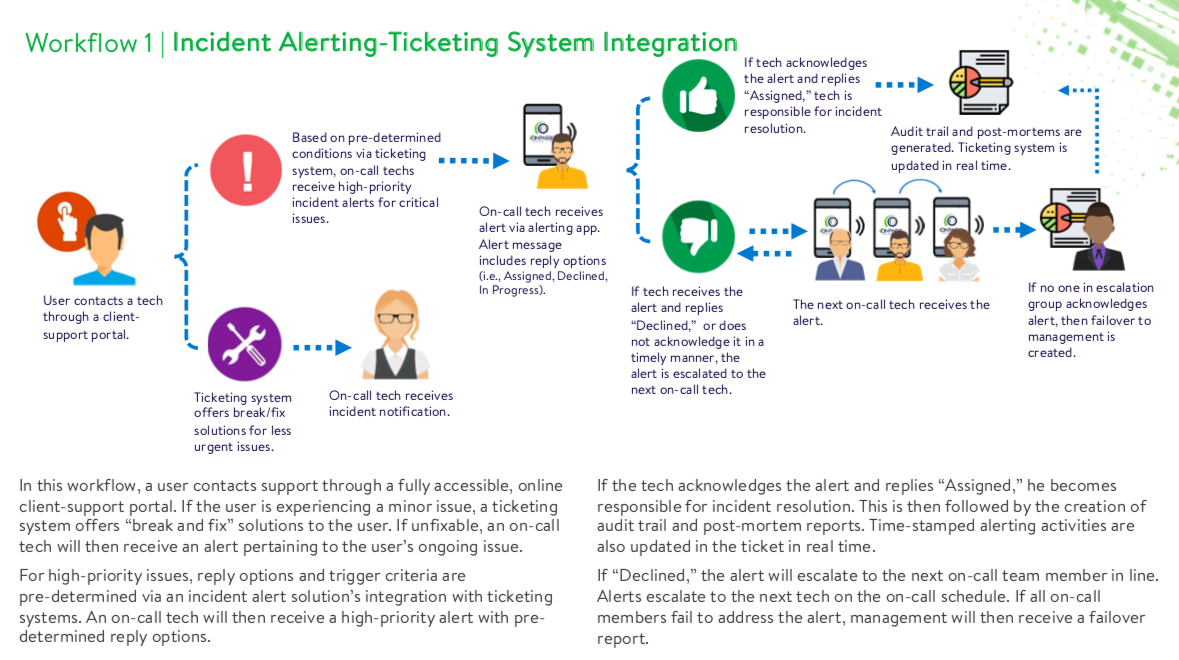
In the case of low-priority issues, an on-call engineer receives “break/fix” solutions from a ticketing system, gaining insight into general fixes for non-urgent matters.
Contrastingly, a high-priority event receives further attention from on-call responders and support teams. In this case, teams use a ticketing system to determine what’s classified as a high-priority issue. An alert is then triggered to and received by an on-call engineer.
High-priority alerts include reply options, allowing the on-call engineer to either accept or reject the notification. If the tech accepts the issue, he’s then responsible for incident resolution. His performance is tracked in real time via an incident alert platform’s reporting capabilities and all alerting activity is added to the corresponding ticket.
If rejected, the alert is escalated to the next on-call engineer until it’s acknowledged. If unaddressed, management will receive a failover report—alongside audit trail and post-mortem documents—to adjust team performance for future incidents.
Workflow Two: Enhancing Ticket Creation
In this workflow, a client contacts his support team through email or voicemail. Prior to ticket generation, the support team creates conditions and scripts, building alert triggers and determining who’s on call.
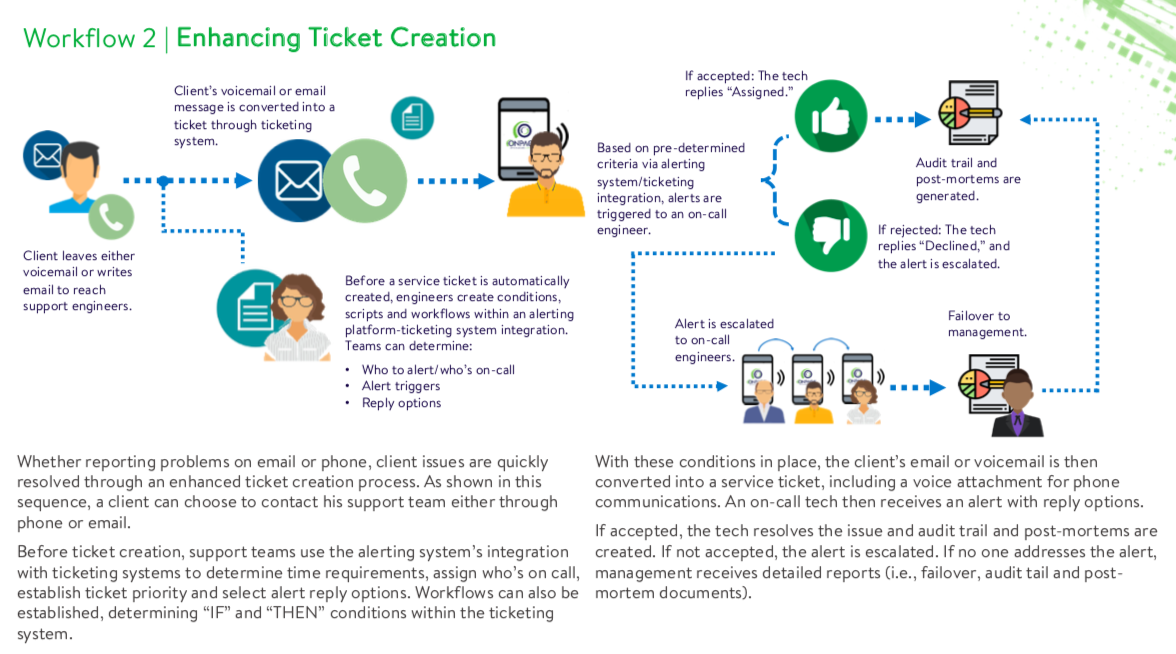
The client’s voicemail or email message is then converted into a service ticket through a ticketing system and its capabilities. An on-call tech will receive an automated mobile alert, equipped with pre-determined reply options.
If accepted, the on-call tech replies “Assigned,” and his performance is tracked and recorded by an alerting platform. Alternatively, if “Declined,” the critical notification is then escalated to the next on-call engineer. On-call team members are assigned and tasked through an alerting platform, with all the details included in the ticket.
Similar to the previous workflow, management receives audit trail, failover and post-mortem documents if the support team fails to address the incident.
Workflow Three: Call Routing, Callback Number
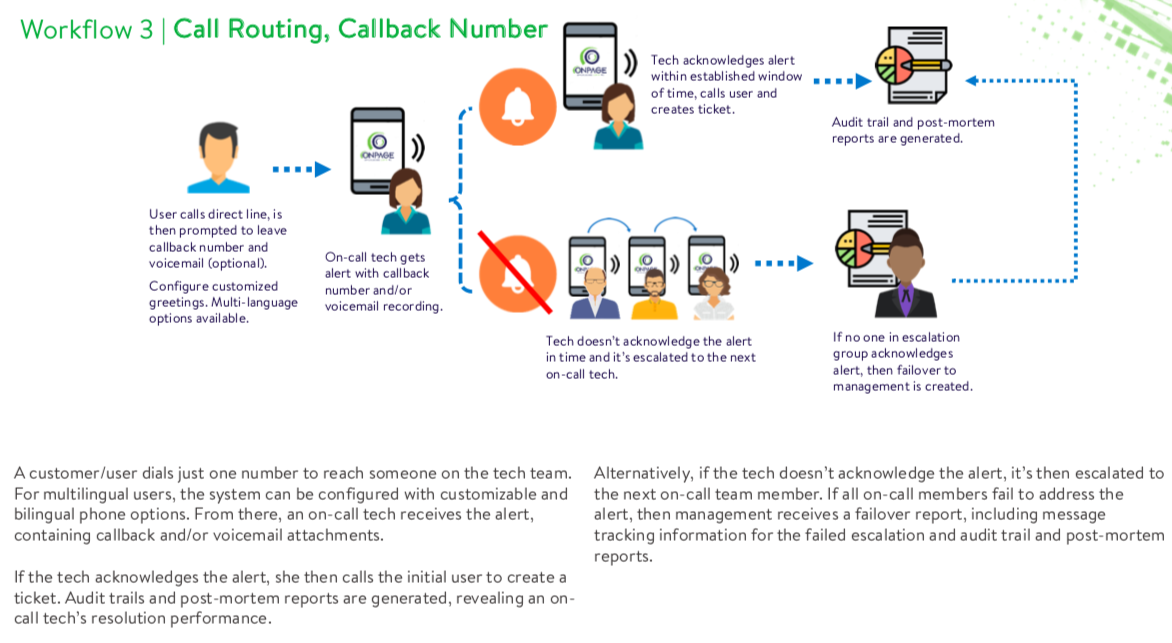
As highlighted in our latest ebook, this sequence is initiated by a client, who dials a dedicated line and leaves a callback number and/or voicemail recording. From there, the client’s message is forwarded to an on-call tech, who receives an alert with contextual information.
If acknowledged, the on-call tech reaches out and calls the client to create a service ticket. The process ends with the creation of audit trail and post-mortem reports.
In the case that the on-call tech misses the alert, the notification escalates to the following team member. Once again, if no one answers the critical alert, management will receive comprehensive reports.
Workflow Four: Live Call Routing
In this final sequence, a client calls a direct line to reach his dedicated support team. The on-call tech receives the call and connects with the user, resolving his IT-related issues and difficulties. Audit trails and post-mortems are then generated.
If no one answers the call, it’s then escalated to the next support team member in line. Ideally, the process ends when support answers the client’s call and resolves his issue. However, if left unaddressed, the client will then leave a callback number and/or voicemail recording. The client’s message (i.e., critical alert) will then be forwarded within the escalation group.
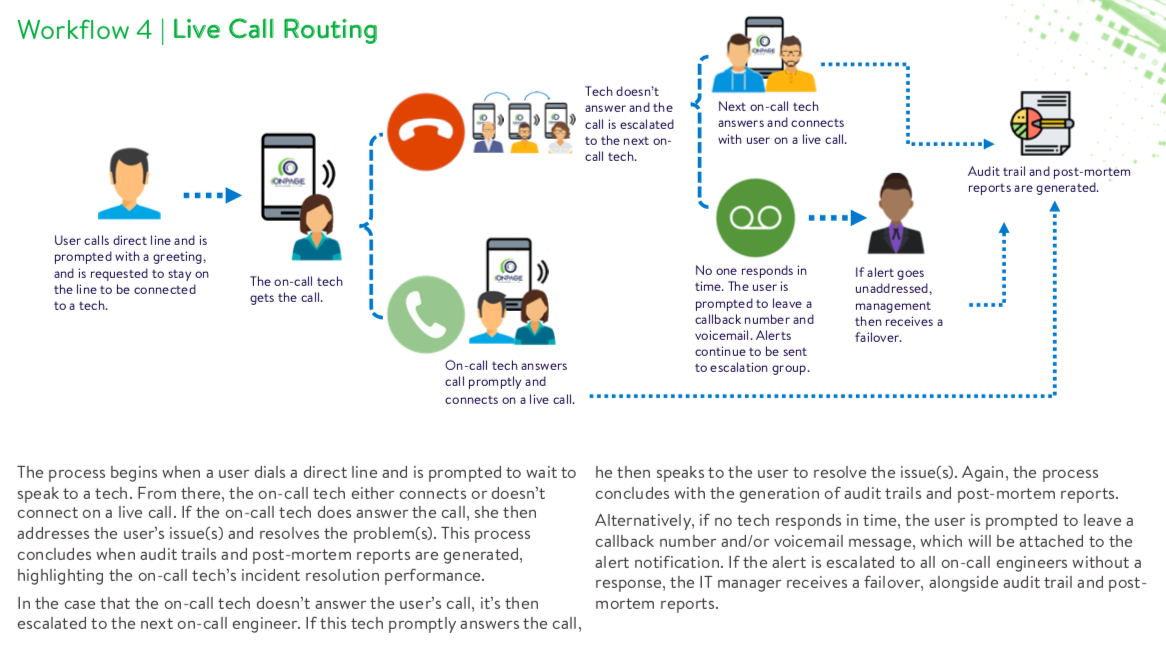
Failure to address the alert results in the creation of reports, which are generated for and received by IT managers. Appropriate action will then be implemented by management, ensuring that future incidents are always addressed and resolved.
As highlighted by this post, incident alert management platforms and processes enhance IT operations and support teams’ day-to-day responsibilities. Tasks are automated and streamlined. These workflows also ensure that incident teams become even more accountable and productive.
Interested to learn more? Contact us or reach sales directly at [email protected].

About The Author




