What’s a Critical Alert?
A critical alert is typically an alert placed at a higher priority level than an alert that comes into the service desk. These alerts are dispatched when there’s an issue that requires immediate attention. Critical alerts, when not responded, can bring an organization’s business process to a standstill, impacting their revenue and bottom line.
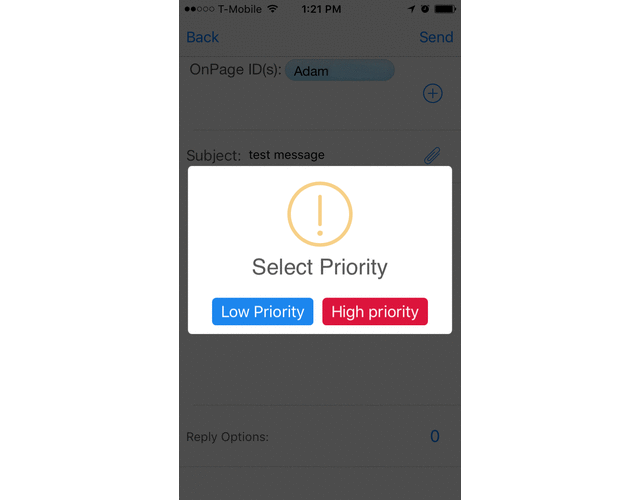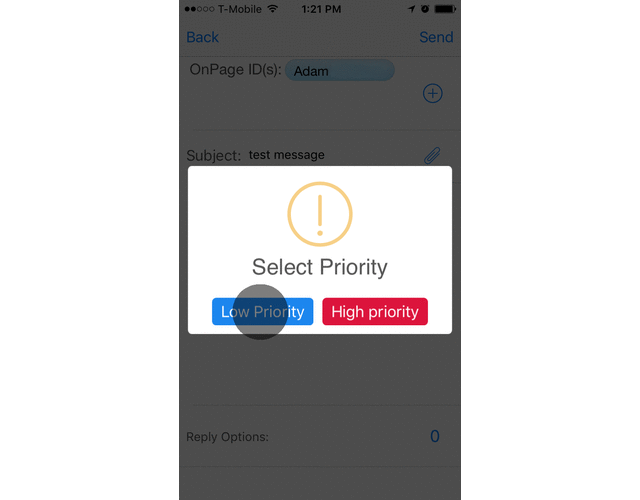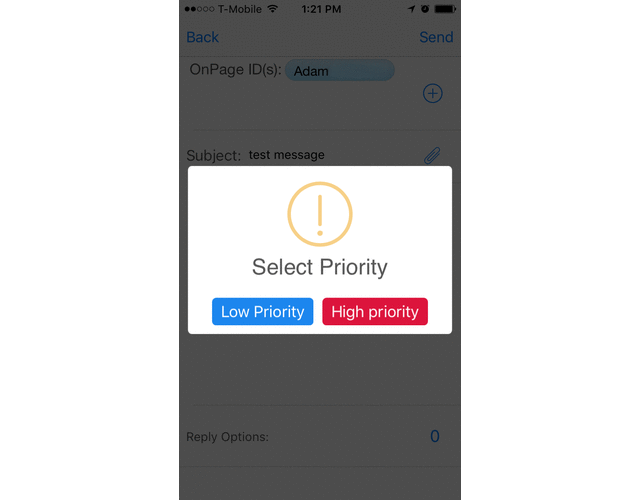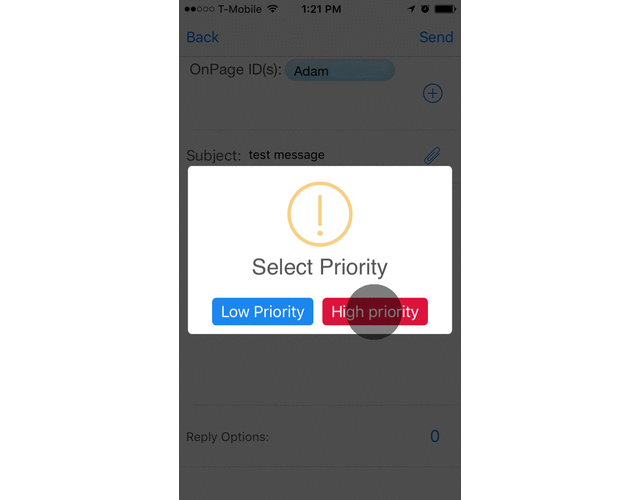
How OnPage prioritizes a critical alert:
A high priority message triggers a loud, intrusive, hard to ignore Alert-Until-Read tone. OnPage alerts mimic the pager urgency but also enables a rich, full text message with voice or picture attachments. Designed for critical, time-sensitive situations, the OnPage alert assures the sender that the message has reached its destination and was read. A good use of the high priority feature is to use it for time-sensitive messaging, urgent messaging, medical emergencies, and critical alerts coming in from monitoring tools.